
A few days ago I wrote about the Friday evening when a single government letter took two of the most capable AI models on the planet offline, and I argued that the real lesson wasn't political — it was architectural. If access to intelligence can be revoked by a third party overnight, then that intelligence is a dependency, and dependency is risk.
That piece ended on a diagnosis. This one is about the cure.
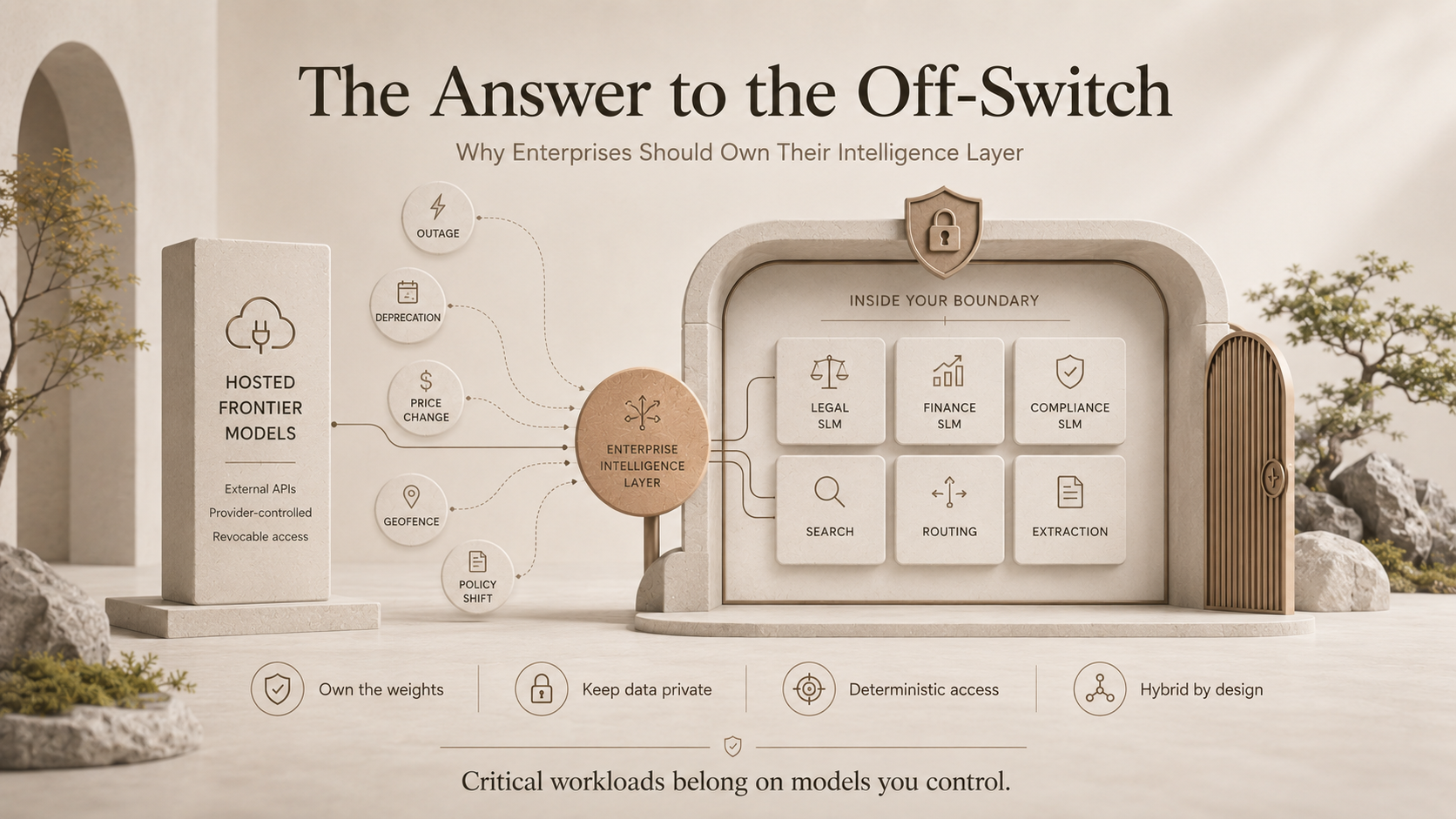
Because once you accept that hosted frontier access can disappear — by government order, by a provider retiring a model, by a pricing change, by a region getting geofenced, by an outage during your busiest hour — the obvious question is: so what do we actually do about it? And the answer, for the workloads that matter most, is the one I've been arguing toward for a long time. You stop renting your most critical capability and start owning it. You train and fine-tune your own small, specialised models, on your own data, running on infrastructure you control.
Let me make that case properly — including the part where I tell you exactly where it's hard, because a strategy that only lists upsides isn't a strategy, it's a sales pitch.
First, an honest calibration
I want to be precise about the claim, because the imprecise version gets people in trouble.
The claim is not "small models beat large models." On broad, open-ended, general-purpose intelligence, frontier LLMs are unmatched, and pretending otherwise damages your credibility the moment someone tests it.
A small model, fine-tuned on your domain, will match or beat a general-purpose frontier model on your domain's specific tasks.
That is not wishful thinking; it's now a well-supported result. Researchers have repeatedly shown that fine-tuning compact models on domain data lets them outperform general LLMs on specialised work in fields like biomedicine and law. A 7-billion-parameter model built for diabetes questions reportedly beat both GPT-4 and Claude 3.5 on that specific task. A 2025 NVIDIA position paper went further, arguing that small models — not larger ones — are the natural foundation for agentic AI. And a recent efficiency study found that models in the 0.5–3B range deliver the best performance-per-unit-of-compute across a range of tasks.
The mechanism is intuitive. A general model spreads its capacity across everything humanity has written. A specialised model spends all of its capacity on your problem — your jargon, your documents, your edge cases, your regulatory context. Depth beats breadth when the task is narrow. The trade is that you give up generality. That's not a bug; it's the entire point.
What you actually gain by owning the model
This isn't theoretical — here's a working example
It's easy to wave at "just train your own model" as if it were a slogan. It isn't anymore. To make this concrete, let me walk through a framework my team built precisely to answer this problem: Auto-Eval-AI, a self-evolving pipeline for owning and continuously improving a domain model end to end.
The base model is Qwen2.5-0.5B — half a billion parameters, roughly a gigabyte, small enough to train and serve comfortably on a single NVIDIA L4 GPU. We pointed it at a biosciences corpus (de-extinction biology, genomic engineering, conservation science), auto-generated more than 5,600 question-answer pairs from the source documents, and ran it through a staged pipeline: supervised fine-tuning on the domain data, then reinforcement learning to protect reasoning, then quantisation for cheap serving — with autonomous drift detection deciding when retraining is even necessary.
The results are the argument in miniature:
- Domain performance went up sharply. Fine-tuning plus retrieval delivered a 26% score improvement over the untuned base model on 141 curated domain questions, winning 51% of pairwise comparisons and scoring 7.0 out of 10 against the base model's 5.0. The model began correctly recalling precise domain facts — extinction dates, population figures, the right technical disambiguations — that the generic model simply got wrong or vague.
- General reasoning was largely preserved. On the GSM8K maths benchmark, specialisation cost only 3.3 percentage points — the model kept about 91.5% of its general reasoning. That is exactly the trade I described above: a large domain gain for a small, measured general loss, with no catastrophic forgetting.
- Serving got cheap. Four-bit compression produced an 11.3× size reduction and a 2.4× inference speed-up. And a quality gate automatically refused to ship a compression level when it degraded quality too far, recommending a safer one instead — automated judgement, not blind compression.
- Nothing left the boundary. The whole optimisation loop, including the autonomous policy evolution that tunes retrieval, runs inside the deployment. No customer data is sent to an external provider during optimisation. For regulated buyers, that property is the whole ballgame.
The deeper point isn't any single number. It's that the entire lifecycle — detect that the model has drifted, decide whether to retrain, find the right hyperparameters, train, evaluate, compress, redeploy — runs as a closed loop with the human expertise encoded once in configuration, then applied repeatedly. Switching the whole thing to a legal or financial domain is a configuration change, not a rebuild. That is what "owning your intelligence layer" looks like in practice: not a one-off model you train and abandon, but a self-maintaining asset that improves on your data, inside your walls, on your hardware.
Where this is genuinely hard — and I won't pretend otherwise
If I only told you the upside, you'd be right to distrust me. So here's the honest ledger.
Owning models means owning MLOps. You need people who can fine-tune, evaluate, and serve models, and that talent isn't free or abundant. You take on GPU capex or committed cloud spend, and the operational burden of keeping a serving stack healthy. And the production scaffolding that hosted APIs give you for free — canary deployments, automatic rollback when quality regresses, a proper model registry — you now have to build. Our own framework is candid that these are the next things to build, not solved problems. Evaluation rigour is another trap: a model that looks great on a hundred curated questions may not be validated enough to trust with a business-critical decision. Owning the model means owning the responsibility to measure it honestly.
None of this is a reason not to do it. It's a reason to do it deliberately, for the workloads that justify it, rather than ripping out every API call in a fit of sovereignty.
The real answer is hybrid, not absolutist
So here's where I land, and it's deliberately not the maximalist position.
The lesson of the off-switch is not "abandon frontier models." Frontier LLMs remain extraordinary for open-ended, general, exploratory work, and most organisations should keep using them for exactly that. The lesson is to stop putting your business-critical, sensitive, can't-go-down workloads on a dependency you don't control. Those workloads — the regulated ones, the proprietary ones, the ones whose downtime is existential — belong on models you own.
The mature architecture is a portfolio. Route open-ended general queries to a frontier model. Route the high-value, sensitive, mission-critical paths to specialised models you've fine-tuned and host yourself. Increasingly this is the enterprise pattern: orchestrate multiple small specialists, or let a large model handle routing and hand off to a domain SLM for the precise answer. You get frontier capability where it helps and sovereign resilience where it counts.
The bottom line
The Fable shutdown proved the off-switch is real and sits in someone else's hand. That fact doesn't go away when the news cycle moves on. The organisations that internalise it will stop optimising purely for which model is smartest and start asking which capabilities can we afford to have revoked — and they'll move those capabilities in-house.
Owning your intelligence layer is no longer the cautious choice of the paranoid. It's available, it's proven, and for an entire class of workloads it is simply the correct architecture. The model you fully control may not be the most capable model in the world. But it's the one that's still running when someone else's gets a letter on a Friday evening.
Build accordingly.
This piece builds on my earlier analysis of the Fable 5 shutdown. The research findings on small-model performance are drawn from published work as of mid-2026; the worked example is from Auto-Eval-AI, a self-evolving model framework my team developed. As always, treat fast-moving claims with appropriate skepticism and validate against your own use case before betting an architecture on them.